---
title: "Classification modeling workflow using tidymodels"
description: "Building a classification pipeline on the Weight Lifting Exercises dataset with tidymodels — workflowsets for cross-validated tuning across four candidate models, plus a stacks ensemble."
author: "Konstantinos Patelis"
date: "2021-04-11"
date-modified: "2026-05-12"
categories: [tidyverse, tidymodels, stacks, XGBoost]
image: index_files/figure-html/plot_hyperparameters_boost-1.png
image-alt: "Grid of accuracy curves across XGBoost hyperparameters from a tidymodels workflowsets tuning run."
bibliography: references.bib
---
A while back, I was working through the final assignment in the Practical Machine Learning Coursera course (part of the [JHU Data Science Specialization](https://www.coursera.org/specializations/jhu-data-science)), which entailed creating a model to predict the way people perform a weight-lifting exercise using data from accelerometers on the belt, forearm, arm, and dumbell of each participant. I thought this was a good opportunity to practice using the [`tidymodels`](https://www.tidymodels.org/) family of packages to tackle this classification problem. So, in this post we will go through the series of steps to create our predictive model. We will cover defining the data pre-processing, specifying the model(s) to fit and using cross-validation to tune model hyperparameters. Additionally, we'll have a look at one of the recent additions to the `tidymodels` packages, `stacks` to create an ensemble model out of our base models. We'll see that most of our models perform almost equally well and an ensemble model is not required for achieving improved accuracy, and is presented mostly because this was a good opportunity to try it out. This blog post documents the approach taken to model this dataset.
::: callout-note
This post has been refreshed since it was first published in April 2021. The modeling section now uses the [`workflowsets`](https://workflowsets.tidymodels.org/) package — which became available on CRAN as I was originally writing the post and which the original conclusion pointed at as the obvious next step — to tune all four candidate models in a single pipeline. Parallel execution has also been migrated from `doParallel` to the `future` framework that `tune` 1.2.0 adopted in 2024. See the *Modified* date in the title block for the refresh date.
:::
### Data
We'll use the Weight Lifting Exercises data set [@velloso2013], provided as part of the Human Activity Recognition project. The data available to us is split in two parts, one is the training set, which contains the `classe` variable which we want to train our model to predict, and the quiz set, that contains 20 observations for which we needed to predict `classe` as part of the course assignment. For this blog post we'll focus on the first data set, which we will split in two parts, one used for actually training the model and one to assess its accuracy.
```{r libraries_and_data, echo=TRUE, warning=FALSE}
## Libraries
# General data wrangling
library(tidyverse)
library(skimr)
# Modeling packages
library(tidymodels)
library(stacks)
# Visualization
library(corrr)
library(plotly)
# Parallelization
library(future)
# EDA - will not be showing the outputs from using these packages, but very useful for exploration
# library(DataExplorer)
# library(explore)
theme_set(theme_bw())
```
```{r read_function, include=FALSE}
read_data <- function(url) {
read_csv(url, col_types = cols(
user_name = col_character(),
raw_timestamp_part_1 = col_character(),
raw_timestamp_part_2 = col_character(),
cvtd_timestamp = col_datetime("%d/%m/%Y %H:%M"),
new_window = col_character(),
num_window = col_double(),
roll_belt = col_double(),
pitch_belt = col_double(),
yaw_belt = col_double(),
total_accel_belt = col_double(),
kurtosis_roll_belt = col_character(),
kurtosis_picth_belt = col_character(),
kurtosis_yaw_belt = col_character(),
skewness_roll_belt = col_character(),
skewness_roll_belt.1 = col_character(),
skewness_yaw_belt = col_character(),
max_roll_belt = col_character(),
max_picth_belt = col_character(),
max_yaw_belt = col_character(),
min_roll_belt = col_character(),
min_pitch_belt = col_character(),
min_yaw_belt = col_character(),
amplitude_roll_belt = col_character(),
amplitude_pitch_belt = col_character(),
amplitude_yaw_belt = col_character(),
var_total_accel_belt = col_character(),
avg_roll_belt = col_character(),
stddev_roll_belt = col_character(),
var_roll_belt = col_character(),
avg_pitch_belt = col_character(),
stddev_pitch_belt = col_character(),
var_pitch_belt = col_character(),
avg_yaw_belt = col_character(),
stddev_yaw_belt = col_character(),
var_yaw_belt = col_character(),
gyros_belt_x = col_double(),
gyros_belt_y = col_double(),
gyros_belt_z = col_double(),
accel_belt_x = col_double(),
accel_belt_y = col_double(),
accel_belt_z = col_double(),
magnet_belt_x = col_double(),
magnet_belt_y = col_double(),
magnet_belt_z = col_double(),
roll_arm = col_double(),
pitch_arm = col_double(),
yaw_arm = col_double(),
total_accel_arm = col_double(),
var_accel_arm = col_character(),
avg_roll_arm = col_character(),
stddev_roll_arm = col_character(),
var_roll_arm = col_character(),
avg_pitch_arm = col_character(),
stddev_pitch_arm = col_character(),
var_pitch_arm = col_character(),
avg_yaw_arm = col_character(),
stddev_yaw_arm = col_character(),
var_yaw_arm = col_character(),
gyros_arm_x = col_double(),
gyros_arm_y = col_double(),
gyros_arm_z = col_double(),
accel_arm_x = col_double(),
accel_arm_y = col_double(),
accel_arm_z = col_double(),
magnet_arm_x = col_double(),
magnet_arm_y = col_double(),
magnet_arm_z = col_double(),
kurtosis_roll_arm = col_character(),
kurtosis_picth_arm = col_character(),
kurtosis_yaw_arm = col_character(),
skewness_roll_arm = col_character(),
skewness_pitch_arm = col_character(),
skewness_yaw_arm = col_character(),
max_roll_arm = col_character(),
max_picth_arm = col_character(),
max_yaw_arm = col_character(),
min_roll_arm = col_character(),
min_pitch_arm = col_character(),
min_yaw_arm = col_character(),
amplitude_roll_arm = col_character(),
amplitude_pitch_arm = col_character(),
amplitude_yaw_arm = col_character(),
roll_dumbbell = col_double(),
pitch_dumbbell = col_double(),
yaw_dumbbell = col_double(),
kurtosis_roll_dumbbell = col_character(),
kurtosis_picth_dumbbell = col_character(),
kurtosis_yaw_dumbbell = col_character(),
skewness_roll_dumbbell = col_character(),
skewness_pitch_dumbbell = col_character(),
skewness_yaw_dumbbell = col_character(),
max_roll_dumbbell = col_character(),
max_picth_dumbbell = col_character(),
max_yaw_dumbbell = col_character(),
min_roll_dumbbell = col_character(),
min_pitch_dumbbell = col_character(),
min_yaw_dumbbell = col_character(),
amplitude_roll_dumbbell = col_character(),
amplitude_pitch_dumbbell = col_character(),
amplitude_yaw_dumbbell = col_character(),
total_accel_dumbbell = col_double(),
var_accel_dumbbell = col_character(),
avg_roll_dumbbell = col_character(),
stddev_roll_dumbbell = col_character(),
var_roll_dumbbell = col_character(),
avg_pitch_dumbbell = col_character(),
stddev_pitch_dumbbell = col_character(),
var_pitch_dumbbell = col_character(),
avg_yaw_dumbbell = col_character(),
stddev_yaw_dumbbell = col_character(),
var_yaw_dumbbell = col_character(),
gyros_dumbbell_x = col_double(),
gyros_dumbbell_y = col_double(),
gyros_dumbbell_z = col_double(),
accel_dumbbell_x = col_double(),
accel_dumbbell_y = col_double(),
accel_dumbbell_z = col_double(),
magnet_dumbbell_x = col_double(),
magnet_dumbbell_y = col_double(),
magnet_dumbbell_z = col_double(),
roll_forearm = col_double(),
pitch_forearm = col_double(),
yaw_forearm = col_double(),
kurtosis_roll_forearm = col_character(),
kurtosis_picth_forearm = col_character(),
kurtosis_yaw_forearm = col_character(),
skewness_roll_forearm = col_character(),
skewness_pitch_forearm = col_character(),
skewness_yaw_forearm = col_character(),
max_roll_forearm = col_character(),
max_picth_forearm = col_character(),
max_yaw_forearm = col_character(),
min_roll_forearm = col_character(),
min_pitch_forearm = col_character(),
min_yaw_forearm = col_character(),
amplitude_roll_forearm = col_character(),
amplitude_pitch_forearm = col_character(),
amplitude_yaw_forearm = col_character(),
total_accel_forearm = col_double(),
var_accel_forearm = col_character(),
avg_roll_forearm = col_character(),
stddev_roll_forearm = col_character(),
var_roll_forearm = col_character(),
avg_pitch_forearm = col_character(),
stddev_pitch_forearm = col_character(),
var_pitch_forearm = col_character(),
avg_yaw_forearm = col_character(),
stddev_yaw_forearm = col_character(),
var_yaw_forearm = col_character(),
gyros_forearm_x = col_double(),
gyros_forearm_y = col_double(),
gyros_forearm_z = col_double(),
accel_forearm_x = col_double(),
accel_forearm_y = col_double(),
accel_forearm_z = col_double(),
magnet_forearm_x = col_double(),
magnet_forearm_y = col_double(),
magnet_forearm_z = col_double(),
problem_id = col_double()
))
}
```
```{r data, warning=FALSE}
## Data
initial_data <- read_data("https://d396qusza40orc.cloudfront.net/predmachlearn/pml-training.csv") %>% select(-1) # read_data is a wrapper around read_csv
```
## EDA
Let's split the initial data a training set and an test set (80/20 split). For the exploratory analysis and subsequent modeling, hyperparameter tuning and model evaluation I will use the training data set. Then the model will be used on the test data to predict out-of-sample accuracy.
```{r}
set.seed(1992)
split <- initial_split(initial_data, prop = .8, strata = classe)
train <- training(split)
test <- testing(split)
skim(train)
```
It seems like the majority of the variables are numeric, but one important thing to note is that there is a high percentage of missing observations for a subset of the variables. From the completion rate, it seems that the missing values across the different attributes occur for the same observations. Since the majority of observations have missing values for these variables, it is unlikely that we could impute them. When viewing the data in spreadsheet applications these variables have a mix of being coded as NA or being simply blank, while even for observations where values are available, there are instances of a value showing as `#DIV/0`.
```{r}
eda <- train %>% select(where(~ !any(is.na(.))))
```
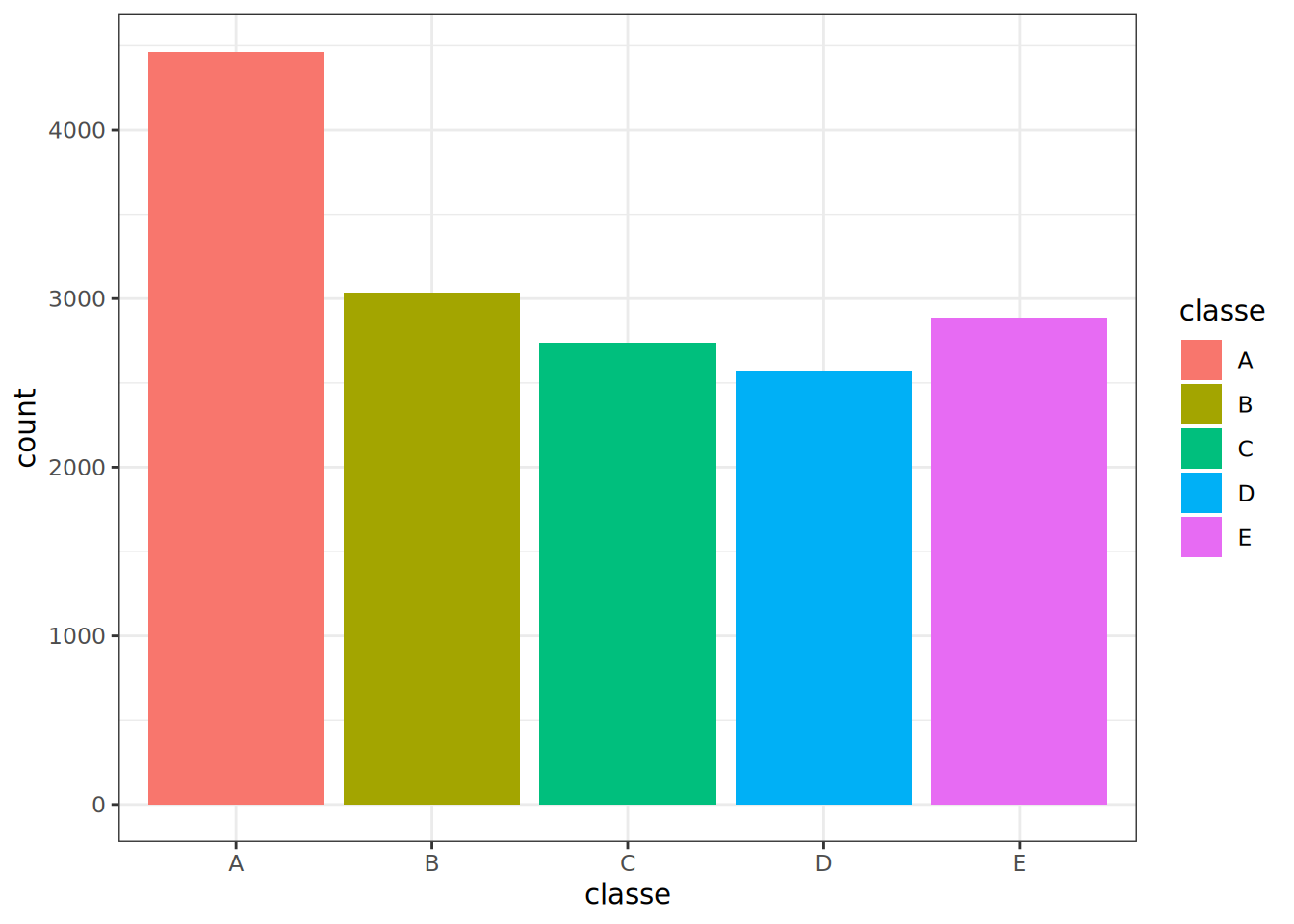
One important thing in classification problems is to investigate whether there is imbalance between the different classes in our training data. For example, if a class is over-represented in the data then our classifier might tend to over-predict that class. Let's check how many times each class appears in the data.
```{r classe}
ggplot(eda, aes(classe, fill = classe)) +
geom_bar() +
theme_bw()
```
Looking at the above, there does not seem to be severe imbalance among classes. The first class, A is represented more compared to the other ones, but it's not to an overwhelming extent.
Considering the other columns in our data, user name cannot be part of our predictors because it cannot generalize to other data if our model was used on data that is not part of this study. Looking at the timestamp, each subject was fully measured at a different point in the day, with each exercise happening back-to-back. From Velloso et al. (2013) [@velloso2013], we know that all subjects were observed in the presence of a professional trainer to observe that the exercise was done according to specification each time. I will not consider the timestamps or any features derived from them (e.g. using the time of day) as a predictor in our models.
```{r}
eda %>%
mutate(new_window = as.numeric(factor(new_window))) %>%
select(where(is.numeric)) %>%
correlate(method = "pearson", quiet = TRUE) %>%
shave() %>%
rplot() %>%
ggplotly()
```
<aside>You can highlight a circle to see the values for which that correlation was calculated, since it's not easy to make it out from the axes.</aside>
Even excluding the columns mentioned above, there are a lot of features and presenting more information on EDA here would get too extensive. Since the purpose here is to demonstrate the modeling process with `tidymodels`, we will not be performing a more extensive EDA. For quick data exploration, you can use `DataExplorer::create_report(eda)` and `explore::explore(eda)` (after installing the two packages) to get a full data report on the data set from the former and a shiny app for interactive exploration from the latter.
## Modeling
In this section we will define the recipe to pre-process the data, specify the candidate models and combine them in a `workflow_set`. We then tune all of them with a single call and compare their performance.
### Pre-processing Recipe
I will use the `recipes` package to provide a specification of all the transformations to the data set before I fit any models, which will ensure that the same transformations are applied to the training, test and quiz data in the same way. Furthermore, it helps avoid information leakage as the transformations will be applied to all data sets using the statistics calculated for the training data. Specifically, I will remove all variables with missing values as well as other attributes discussed above, perform a transformation to try to make all predictors more symmetric (which is useful for models that benefit from predictors with distributions close to the Gaussian), normalize all variables (particularly important for the KNN and glmnet models) and then removing any predictors, if any, with very small variance. Note that we could define different pre-processing steps if required by the various models we will be tuning.
```{r recipe}
# Creating a vector with the names of all variables that should be removed because they contain NAs
cols_rm <- train %>%
select(where(~ any(is.na(.)))) %>%
colnames()
model_recipe <- recipe(classe ~ ., data = train) %>%
step_rm(all_of(!!cols_rm), all_nominal_predictors(),
cvtd_timestamp, num_window,
new_window) %>%
step_YeoJohnson(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_nzv(all_numeric_predictors())
# Below rows can be used to perform the transformation on the training set. Since we will be using the workflow package, this is not required.
# model_recipe_prepped <- model_recipe %>% prep()
# baked_recipe <- model_recipe_prepped %>% bake(new_data = NULL)
```
### Model Specification
In this section I will use the `parsnip` package to create model specifications and set which model parameters will need to be tuned to ensure higher model performance. I will be trying four different models:
1. Random Forests (rf) - with 1000 trees and we will tune the number of predictors at each node split and the minimum number of data points in a node required for the node to be further split.
2. K Nearest Neighbours (knn) - with a tunable number k of neighbours, kernel function with which to weight distances, and the parameter for the Minkowski distance.
3. Multinomial Logistic Regression with Regularization (lm) - with a tunable regularization penalty.
4. Boosted Trees (boost) - where we tune the number of trees, the learning rate, tree depth, number of predictors at each node split and the minimum number of data points in a node.
With `parsnip` we can create the specification in a similar manner across models and specify "computational engines" - practically R functions/packages that implement the calculations.
```{r mode_specification}
rf_model <- rand_forest(
mtry = tune(),
min_n = tune(),
trees = 1000
) %>%
set_engine("ranger") %>%
set_mode("classification")
# rf_fit <- fit(rf_model, classe ~ ., data = baked_recipe) # This call could be used to fit the model to the training data, but we will be using the workflows interface
knn_model <- nearest_neighbor(
neighbors = tune(),
weight_func = tune(),
dist_power = tune()
) %>%
set_engine("kknn") %>%
set_mode("classification")
# knn_fit <- fit(knn_model, classe ~ ., data = baked_recipe)
lasso_model <- multinom_reg(
penalty = tune(),
mixture = 1
) %>%
set_engine("glmnet")
# lasso_fit <- fit(lasso_model, classe ~ ., data = baked_recipe)
boost_model <- boost_tree(
trees = tune(),
mtry = tune(),
min_n = tune(),
learn_rate = tune(),
tree_depth = tune()
) %>%
set_engine("xgboost") %>%
set_mode("classification")
# boost_fit <- fit(boost_model, classe ~ ., data = baked_recipe)
```
Instead of building one `workflow` per model, we use the `workflowsets` package to pair the single pre-processing recipe with each of the four model specs in one go. The resulting `workflow_set` is a tibble with one row per model, and the rest of the modelling section operates on it directly.
```{r workflows}
wfs <- workflow_set(
preproc = list(rec = model_recipe),
models = list(rf = rf_model, knn = knn_model, lasso = lasso_model, boost = boost_model)
)
wfs
```
### Model Tuning
Let us tune the different model parameters using 10-fold cross-validation. To create the grid with the combinations of parameters we can use a space-filling design with 30 points, based on which 30 combinations of the parameters will be picked such that they cover the most area in the design space. The `dials` package contains sensible default ranges for the most common hyperparameters that are tuned in models. The user can modify those if required, and for some, the default range depends on the number of features. One such example is the `mtry` parameter in random forests and boosted trees algorithms, whose max value is equal to the number of predictors in the processed data set. Since the number of predictors is known after preparing the recipe, we use `finalize()` to set the upper bound of `mtry` for the two affected models and then attach those parameter sets to the relevant rows of the workflow set via `option_add()`.
```{r model_parameters}
# Number of predictors after pre-processing — needed to finalize mtry for rf and boost.
trained_data <- model_recipe %>% prep() %>% bake(new_data = NULL)
rf_param <- extract_parameter_set_dials(rf_model) %>% finalize(trained_data)
boost_param <- extract_parameter_set_dials(boost_model) %>% finalize(trained_data)
wfs <- wfs %>%
option_add(param_info = rf_param, id = "rec_rf") %>%
option_add(param_info = boost_param, id = "rec_boost")
rf_param %>% extract_parameter_dials("mtry")
```
When tuning a model, it is always important to consider what we are trying to optimize the model (e.g. achieve highest possible accuracy, maximize true positives, etc). For our problem, the aim is to accurately predict the class of each observation, so at the end of the tuning process we will pick the hyperparameters that achieve highest accuracy. We pass an explicit `metric_set(accuracy, roc_auc)` to `workflow_map()` so that probability predictions (`roc_auc`) are also produced — they're needed downstream by `stacks`. Parallel execution is handled by the `future` framework, which `tune` 1.2.0 adopted in 2024 in place of the older `foreach`/`doParallel` setup.
```{r model_tuning}
set.seed(9876)
folds <- vfold_cv(data = train, v = 10, strata = classe)
plan(multisession, workers = 10)
tuned_set <- wfs %>%
workflow_map(
"tune_grid",
resamples = folds,
grid = 30,
metrics = metric_set(accuracy, roc_auc),
control = control_grid(
save_pred = TRUE,
save_workflow = TRUE,
allow_par = TRUE,
parallel_over = "resamples"
),
seed = 1992,
verbose = TRUE
)
plan(sequential)
```
### In-sample Accuracy
One can use the `collect_metrics()` function — or its workflow-set counterparts like `extract_workflow_set_result()` and `rank_results()` — to visualize the average accuracy for each combination of parameters (averaging across resamples), and see the various hyperparameters that achieve such accuracy.
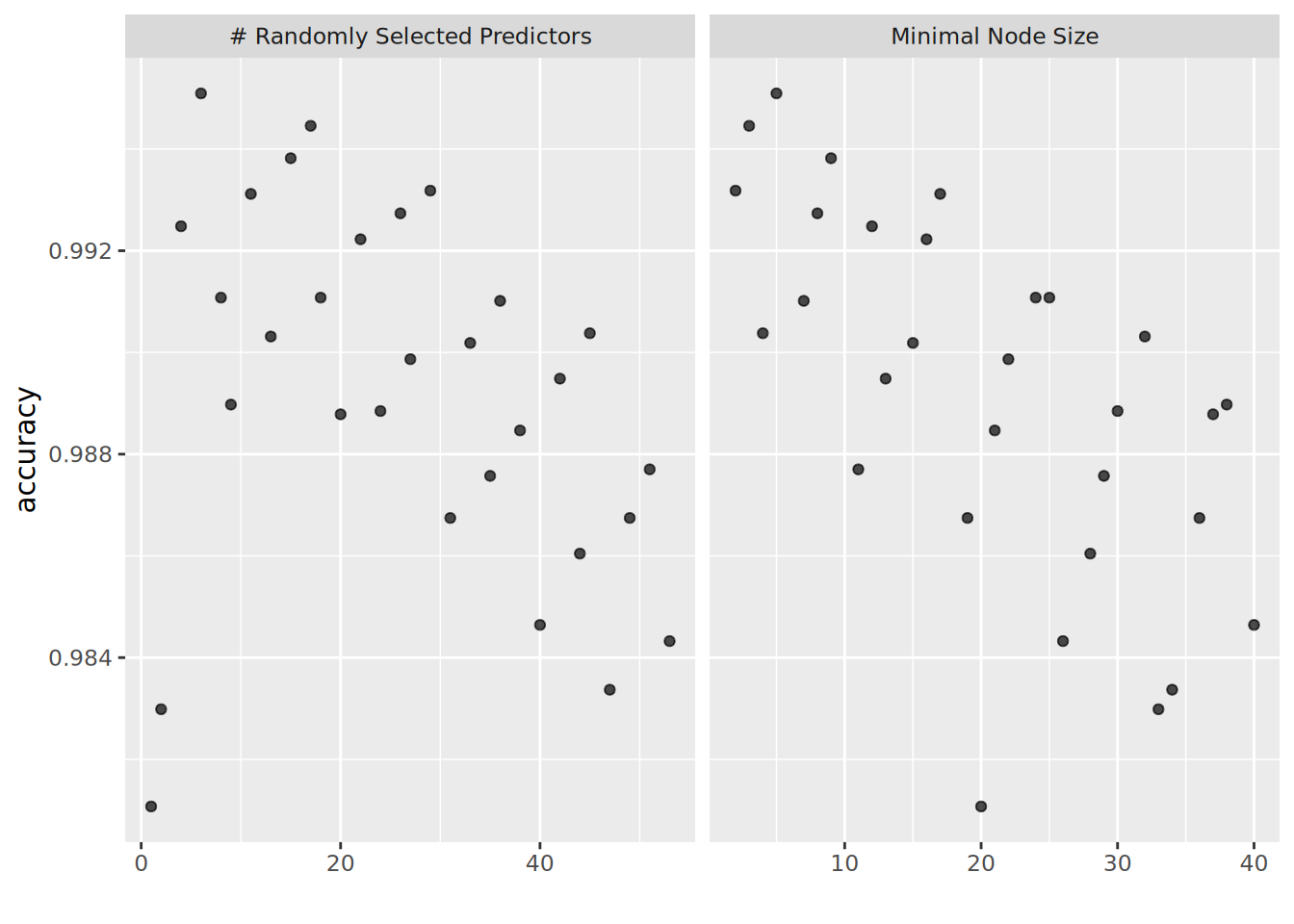
```{r plot_hyperparameters_rf}
tuned_set %>% extract_workflow_set_result("rec_rf") %>% autoplot(metric = "accuracy")
```
We can see that for the random forests model a combination of around 15-20 predictors and a minimal node size in the range between 5-15 seem to be optimal.
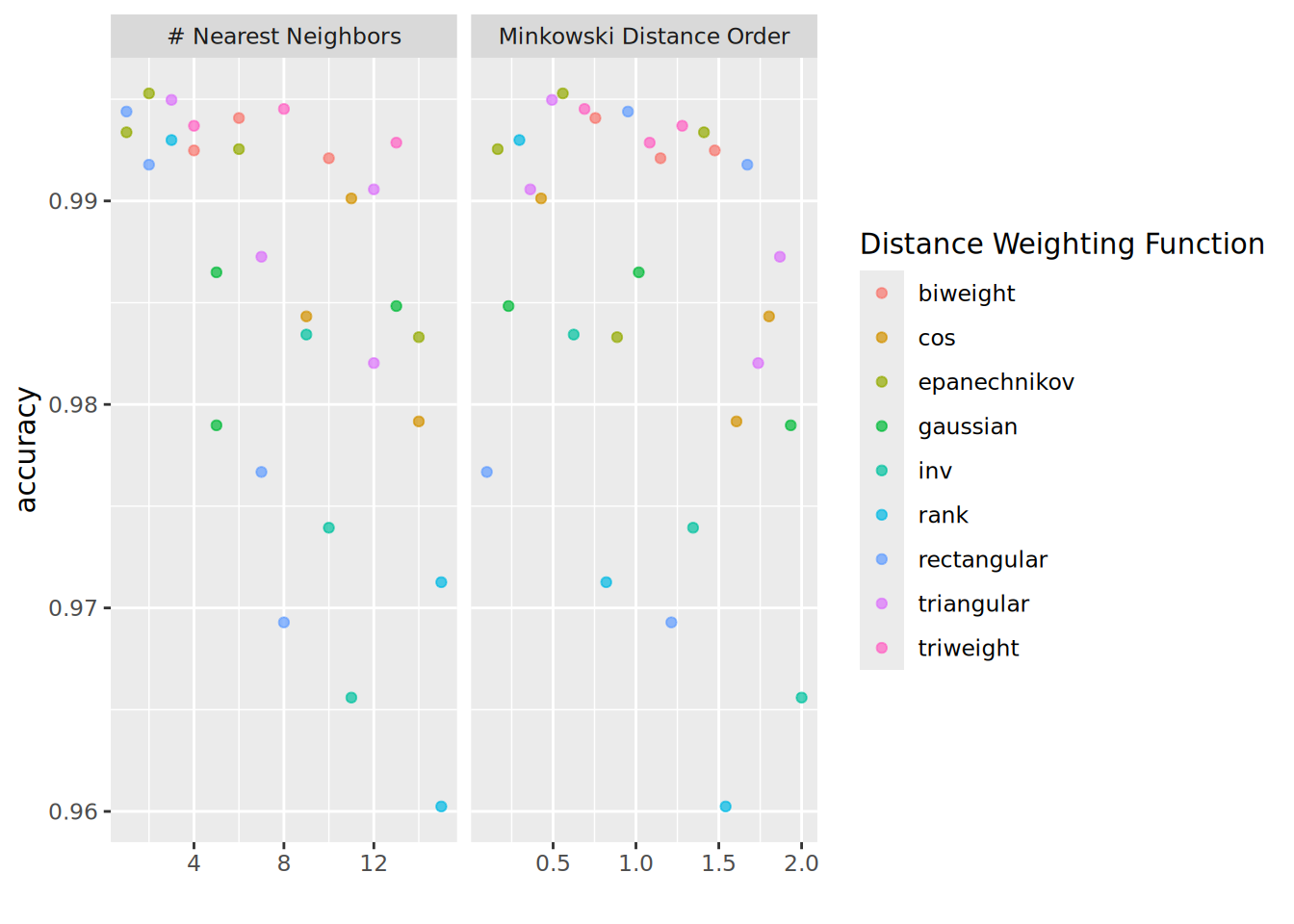
```{r plot_hyperparameters_knn}
tuned_set %>% extract_workflow_set_result("rec_knn") %>% autoplot(metric = "accuracy")
```
For K-NN, a small number of neighbours is preferred, while Minkowski Distance of order 0.25 seems to perform best.
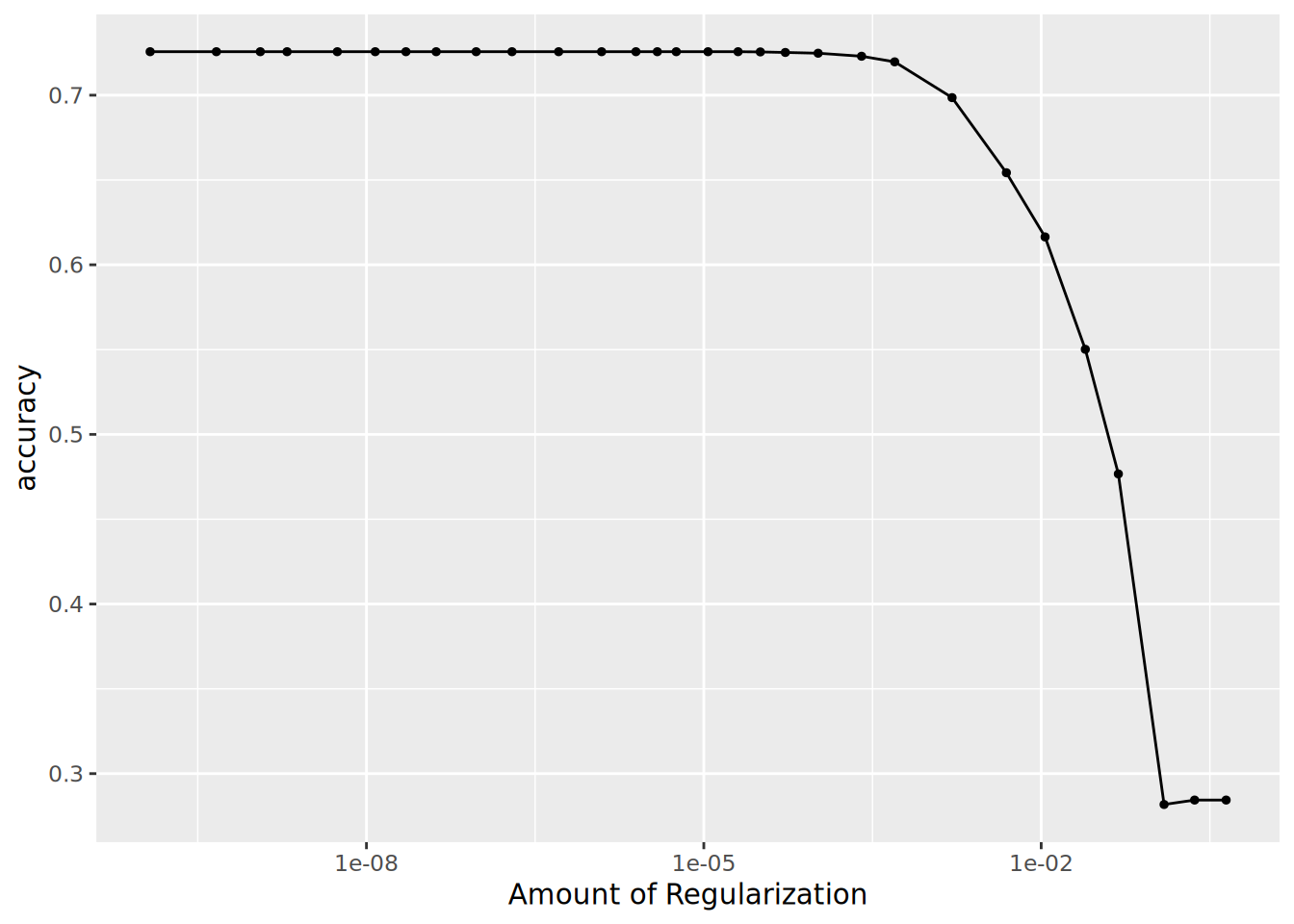
```{r plot_hyperparameters_lm}
tuned_set %>% extract_workflow_set_result("rec_lasso") %>% autoplot(metric = "accuracy")
```
Small penalty is preferred for the LASSO model and it seems that up to a point, similar accuracy levels are achieved.
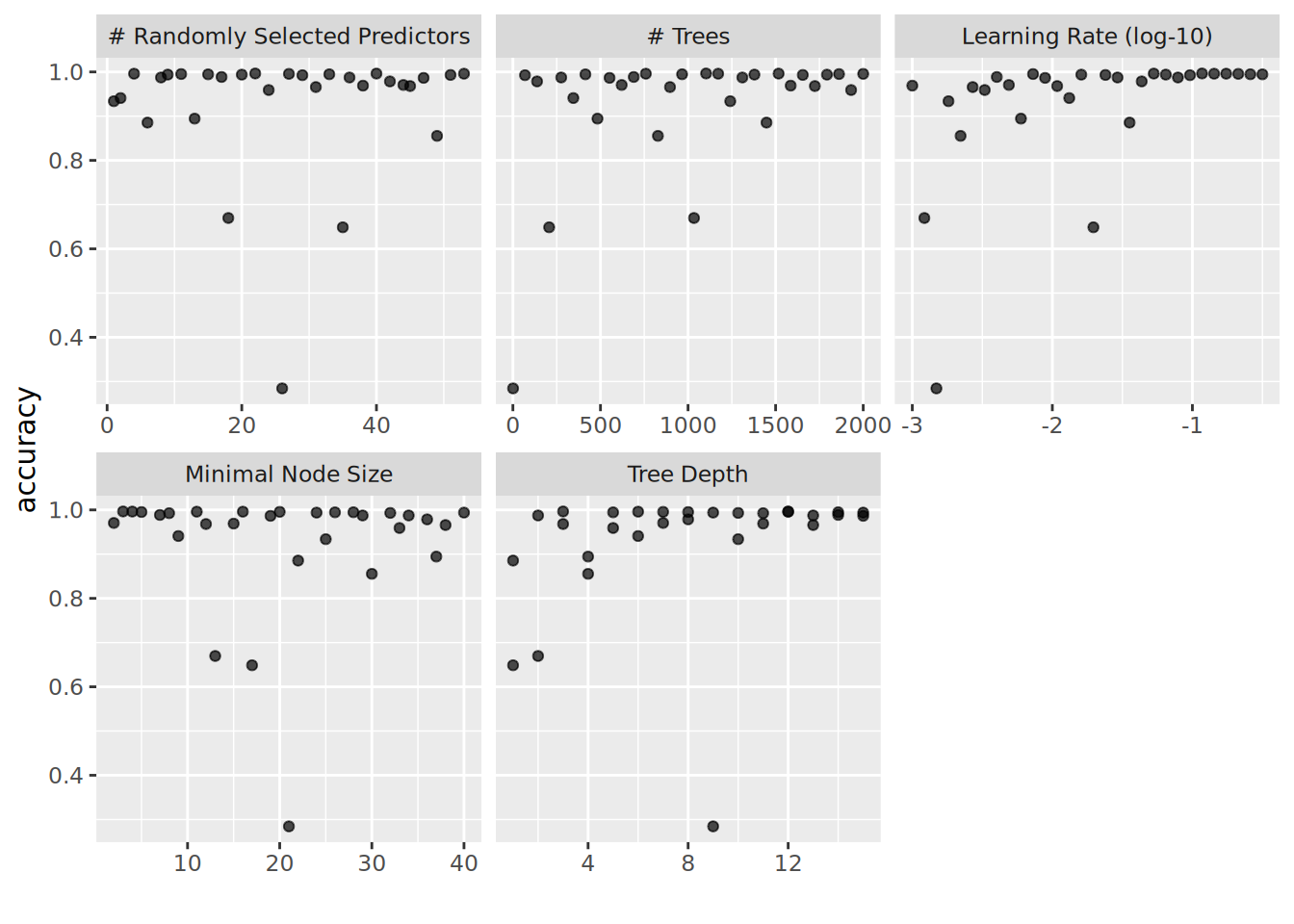
```{r plot_hyperparameters_boost}
tuned_set %>% extract_workflow_set_result("rec_boost") %>% autoplot(metric = "accuracy")
```
For boosted trees, it seems that a higher learning rate is better. Higher tree depth (especially in the range of 9-14) seems to provide best results, while the number of trees and the minimal node size seem to have a wide range of values for which we achieve increased accuracy.
Let us select the best models from each type of model and compare in-sample accuracy. `rank_results()` will pull the best configuration per workflow in one call.
```{r best_models}
model_labels <- c(
rec_rf = "Random Forest",
rec_knn = "K-NN",
rec_lasso = "Logistic Reg",
rec_boost = "Boosted Trees"
)
rank_results(tuned_set, rank_metric = "accuracy", select_best = TRUE) %>%
filter(.metric == "accuracy") %>%
transmute(model = model_labels[wflow_id], accuracy = mean) %>%
arrange(desc(accuracy)) %>%
knitr::kable()
```
We can see that the random forests, K-NN, and boosted trees models perform exceptionally on the resamples of the train data, while even the best lasso logistic regression model performs much worse than the other three. However, there is high chance that our models have overfit on the training data and actually will not perform as well when generalizing to new data. This is where out-of-sample data comes to play, as we will use the portion of the data we set aside at the beginning to calculate accuracy on new data.
### Out-of-sample Accuracy
Now that we have a set of hyperparameters that optimize performance for each model, we can update each workflow with its best parameters, fit on the entire training set and predict on the held-out test set. With `workflowsets` this becomes a single `map` over the rows of the tuned set rather than four separate finalize-and-fit blocks.
```{r out_of_sample}
last_fits <- tibble(
wflow_id = c("rec_rf", "rec_knn", "rec_lasso", "rec_boost"),
pretty = c("Random Forest", "K-NN", "LASSO LogReg", "Boosted Trees"),
seed = c(1209L, 1387L, NA_integer_, 54678L)
) %>%
mutate(
final_wf = map(wflow_id, ~ {
wf <- extract_workflow(tuned_set, .x)
best <- tuned_set %>% extract_workflow_set_result(.x) %>% select_best(metric = "accuracy")
finalize_workflow(wf, best)
}),
final_fit = map2(final_wf, seed, ~ {
if (!is.na(.y)) set.seed(.y)
last_fit(.x, split)
})
)
last_fits %>%
transmute(model = pretty, .metrics = map(final_fit, collect_metrics)) %>%
unnest(.metrics) %>%
filter(.metric == "accuracy") %>%
select(model, accuracy = .estimate) %>%
arrange(desc(accuracy)) %>%
knitr::kable()
```
We can see that the boosted trees and k nearest neighbours models perform great, with random forest trailing slightly behind. The LASSO logistic regression model has much lower performance and would not be preferred. At this point we could walk away with a model that has a 99.8% accuracy on unseen data. However, we can take it a couple of steps further to see if we can achieve even greater accuracy, as we'll see in the next sections.
### Ensemble Model
In the previous section we used the `tune` package to try out different hyperparameter combinations over our data and estimate model accuracy using cross-validation. Let's assume we haven't yet tested the best model on our test data as we're only supposed to use the test set for final selection and we shouldn't be using the knowledge from applying to test data to improve performance. Because each workflow in `tuned_set` was tuned with `save_pred = TRUE` and `save_workflow = TRUE`, we can pass the whole workflow set to `stacks::add_candidates()` in one call — since `stacks` 0.2.2, the helper accepts a `workflow_set` directly. The reason we kept `roc_auc` as a metric while tuning is because it creates soft predictions, which are required in classification problems to create the stack. Since the outputs of these models will be highly correlated, the `blend_predictions` function performs regularization to decide which outputs will be used in the final prediction. For the multinomial blend we use `mn_log_loss` (multinomial log loss) rather than `accuracy` — `accuracy` is not smooth in the predicted-probability space, which on a multiclass outcome can lead the LASSO blender to shrink every candidate coefficient to zero and produce an empty stack ([tidymodels/stacks#225](https://github.com/tidymodels/stacks/issues/225)).
```{r create_stack}
set.seed(5523)
model_stack <- stacks() %>%
add_candidates(tuned_set) %>%
blend_predictions(metric = metric_set(mn_log_loss))
model_stack_fit <- model_stack %>% fit_members()
class_levels <- levels(factor(train$classe))
pred_cols <- paste0(".pred_", class_levels)
stack_pred_test <- test %>%
bind_cols(predict(model_stack_fit, new_data = ., type = "prob")) %>%
mutate(
.pred_class = factor(
class_levels[max.col(across(all_of(pred_cols)), ties.method = "first")],
levels = class_levels
)
)
```
```{r stack_accuracy}
stack_pred_test %>%
mutate(classe = factor(classe, levels = class_levels)) %>%
accuracy(classe, .pred_class) %>%
knitr::kable()
```
We see that in the end we achieved the same accuracy as our best model, which is not unexpected considering our accuracy was almost perfect. We can also have a look at the weights of the different models used in the ensemble.
```{r stack_plot}
autoplot(model_stack_fit, type = "weights") %>%
ggplotly()
```
<aside>We can see our ensemble assigned high weights to boost_tree models, you'll need to zoom in to see the weights for other models.</aside>
While there was not much room for improvement, as mentioned in the beginning, this was a good opportunity to play around with the new package in practice.
Although this data set did not present much of a challenge in terms of predicting the outcome, we managed to cover many of the different steps in the modeling process using `tidymodels`. The updated version of this post leans on [`workflowsets`](https://workflowsets.tidymodels.org/) — the package the original 2021 post pointed at as future work — to express the four-model tuning sweep as a single pipeline, and on the `future` backend that `tune` 1.2.0 adopted for parallel execution. Further steps one could take in this analysis could potentially involve using functionality from the `tidyposterior` package to make statistical comparisons between the models we constructed that performed similarly.